amep.evaluate.ClusterSizeDist#
- class amep.evaluate.ClusterSizeDist(traj: ParticleTrajectory | FieldTrajectory, skip: float = 0.0, nav: int = 10, include_single: bool = False, ptype: int | None = None, ftype: str | list | None = None, use_density: bool = True, logbins: bool = False, xmin: float | None = None, xmax: float | None = None, nbins: int | None = None, **kwargs)#
Bases:
BaseEvaluationClustersize distribution.
- __init__(traj: ParticleTrajectory | FieldTrajectory, skip: float = 0.0, nav: int = 10, include_single: bool = False, ptype: int | None = None, ftype: str | list | None = None, use_density: bool = True, logbins: bool = False, xmin: float | None = None, xmax: float | None = None, nbins: int | None = None, **kwargs) None#
Calculate the weighted cluster size distribution.
Takes an average over several frames. The calculation is based on a histogram of the cluster sizes.
Notes
The weighted cluster size distribution is defined by
\[p(m) = m \frac{n_m}{N},\]where m is the cluster size, n_m the number of clusters with size m, and N the total number of particles. See Ref. [1] for further information.
References
- Parameters:
traj (ParticleTrajectory or FieldTrajectory) – Trajectory object.
skip (float, optional) – Skip this fraction at the beginning of the trajectory. The default is 0.0.
nav (int, optional) – Maximum number of frames to consider for the average. The default is 10.
include_single (bool, optional) – If True, single-particle clusters are included in the histogram. The default is False.
ptype (float, optional) – Particle type. If None, all particles are considered. The default is None.
ftype (str or None, optional) – Allows to specify for which field in the given FieldTrajectory the cluster size distribution should be calculated. If None, the cluster size distribution is calculated for the first field in the list of ftype keys and a warning is printed. The default is None.
use_density (bool, optional) – Decides wether to use the integrated value of the field or the area as clustersize. Only set to false if your field cannot be interpreted as a density, i.e., if it can be negative. The default is True.
logbins (bool, optional) – If True, logarithmic bins are used. The default is False.
xmin (float or None, optional) – Minimum value of the bins. The default is None.
xmax (float or None, optional) – Maximum value of the bins. The default is None.
nbins (int or None, optional) – Number of bins. The default is None.
**kwargs – Other keyword arguments are forwarded to amep.cluster.identify and amep.continuum.identify_clusters for ParticleTrajectories and FieldTrajectories, respectively.
- Return type:
None.
Examples
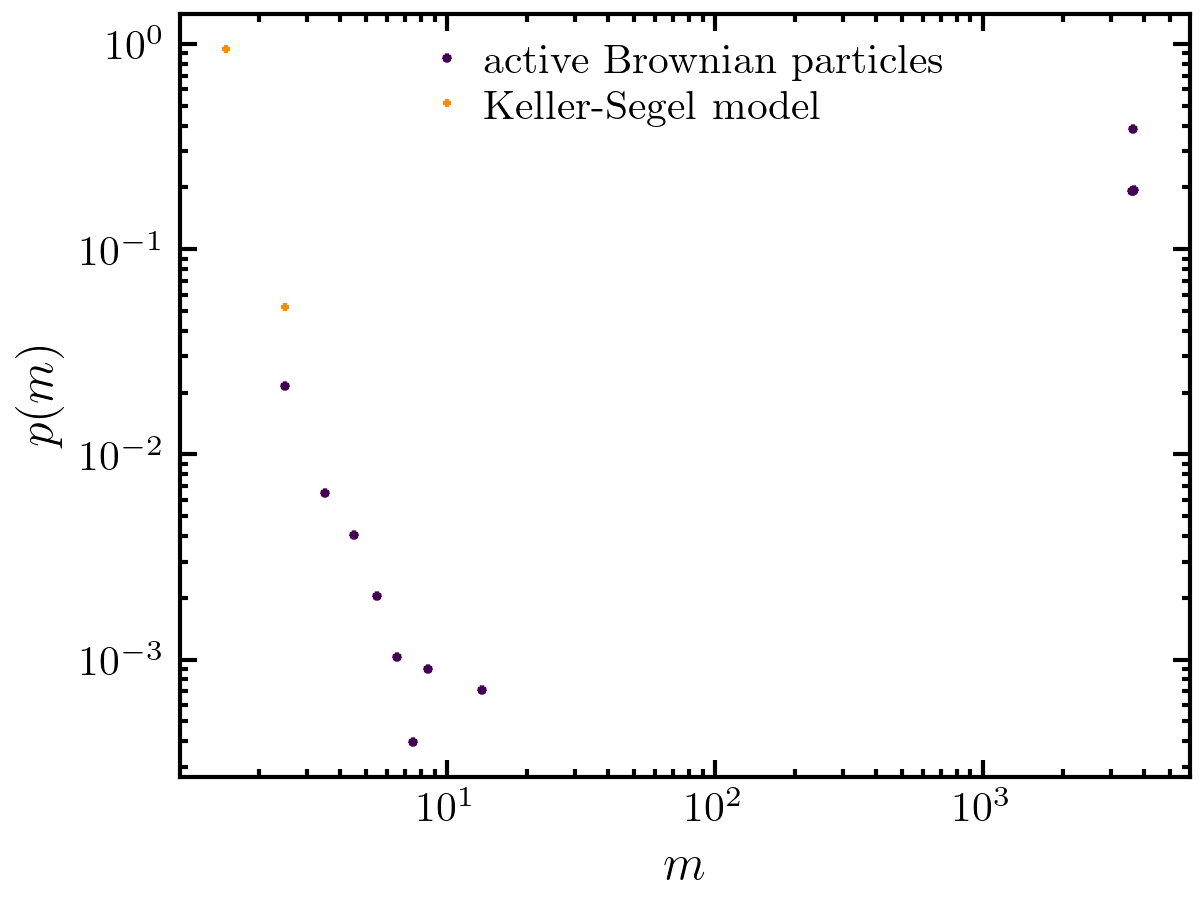
>>> import amep >>> ptraj = amep.load.traj("../examples/data/lammps.h5amep") >>> ftraj = amep.load.traj("../examples/data/continuum.h5amep") >>> pcsd = amep.evaluate.ClusterSizeDist( ... ptraj, nav=5, pbc=True, skip=0.8 ... ) >>> fcsd = amep.evaluate.ClusterSizeDist( ... ftraj, nav=5, pbc=True, skip=0.5, ftype="p", ... use_density=False, threshold=0.2 ... ) >>> pcsd.save("./eval/csd-eval.h5", database=True, name="particles") >>> fcsd.save("./eval/csd-eval.h5", database=True, name="field") >>> fig, axs = amep.plot.new() >>> axs.plot( ... pcsd.sizes, pcsd.avg, marker="*", ls="", ... label="active Brownian particles" ... ) >>> axs.plot( ... fcsd.sizes, fcsd.avg, marker="+", ls="", ... label="Keller-Segel model", color="darkorange" ... ) >>> axs.loglog() >>> axs.set_xlabel(r"$m$") >>> axs.set_ylabel(r"$p(m)$") >>> axs.legend() >>> fig.savefig("./figures/evaluate/evaluate-ClusterSizeDist.png")
Methods
__init__(traj[, skip, nav, include_single, ...])Calculate the weighted cluster size distribution.
items()keys()save(path[, backup, database, name])Stores the evaluation result in an HDF5 file.
values()Attributes
Time-averaged ClusterSizeDist (averaged over the given number of frames).
ClusterSizeDist for each frame.
Indices of all frames for which the ClusterSizeDist has been evaluated.
nameCluster sizes (as number of particles).
Times at which the ClusterSizeDist is evaluated.
- property avg#
Time-averaged ClusterSizeDist (averaged over the given number of frames).
- Returns:
Time-averaged ClusterSizeDist.
- Return type:
various
- property frames#
ClusterSizeDist for each frame.
- Returns:
ClusterSizeDist for each frame.
- Return type:
np.ndarray
- property indices#
Indices of all frames for which the ClusterSizeDist has been evaluated.
- Returns:
Frame indices.
- Return type:
np.ndarray
- save(path: str, backup: bool = True, database: bool = False, name: str | None = None) None#
Stores the evaluation result in an HDF5 file.
- Parameters:
path (str) – Path of the ‘.h5’ file in which the data should be stored. If only a directory is given, the filename is chosen as self.name. Raises an error if the given directory does not exist or if the file extension is not ‘.h5’.
backup (bool, optional) – If True, an already existing file is backed up and not overwritten. This keyword is ignored if database=True. The default is True.
database (bool, optional) – If True, the results are appended to the given ‘.h5’ file if it already exists. If False, a new file is created and the old is backed up. If False and the given ‘.h5’ file contains multiple evaluation results, an error is raised. In this case, database has to be set to True. The default is False.
name (str or None, optional) – Name under which the data should be stored in the HDF5 file. If None, self.name is used. The default is None.
- Return type:
None.
- property sizes#
Cluster sizes (as number of particles).
- Returns:
Cluster sizes.
- Return type:
np.ndarray
- property times#
Times at which the ClusterSizeDist is evaluated.
- Returns:
Times at which the ClusterSizeDist is evaluated.
- Return type:
np.ndarray